An Analogy of Optimization
Most optimization methods can be understood by the analogy of trying to find the highest (or lowest) place in an extremely foggy terrain aided just with an altimeter and a GPS. In real life the GPS gives you your current location in terms of latitude and longitud and can be represented as point in a 2D-space; your location will be called a solution which is usually represented by the letter X. In general X is an N-dimensional space, but for the analogy we just need two dimensions. In the landscape you are exploring you can know the height at each location by using your altimeter. Since the height measured by the altimeter depends on your location, you can say that the altitud is a function f of the location X; this function f is usually called the objetive function.Now remember that the terrain you are in is extremely foggy which means that you cannot see anything that gives you clues as to a where the highest or lowest place might be therefore you can only use your altimeter, GPS and maybe information like the slope at your current location to guide you around. If you wanted to find that optimal place in such conditions you could follow a series of instructions that try get you where you want in the least amount of time.
Basic Concepts
Some of the basic concepts where already introduced in the previous section, in this section however they will be discussed with more detail.
Function and Solution
Say that you have a problem that depends on 2 factors or variables, such a problem could be finding the highest place within a foggy lanscape as it had been suggested. Now, say that you read your position from a GPS which gives you your latitud and longitud; call the latitud the variable x1 and the longitud the variable x2. Now you can group both variables in a vector X defined as
 In this case X is a 2 dimensional vector. Now at any given location Xi you have a certain altitud f, therefore f can be represented as a function of X. For this example, lets imagine that such a function was
In this case X is a 2 dimensional vector. Now at any given location Xi you have a certain altitud f, therefore f can be represented as a function of X. For this example, lets imagine that such a function was




where exp is the exponential function. The graph of this function is

Now, remember that you can't actually see the terrain, you dont have a map or graph as we do here, instead you are going to have to "start wondering around" until of find a set of coordinates X* that you are satisfied with (give you a good height).
Direction and Step
Previously it was stated that you had to "start wondering around" without specifying what this actually meant. Intuitively you know that if you want to get somewhere else of where you are now you have to move, but how can you specify that precisely? Say you are at a location Xi but you want to get to a specific location Xi+1, to do that you have to move the quantity M = Xi+1 - Xi. However, you usually dont know where you want to be, instead you can use certain heuristics to to get a good direction of where to travel. Therefore, it is better to decompose M as the product λd and solve for Xi+1 as
where d is a vector that represents the direction and λ is a non-negative scalar which represents the advance step. Basically λ tells you how much to advance in the direction d, meaning that if λ = 1 then you advance exactly d, if λ < 1 then you advance less than d and if λ > 1 then you advance more than d.
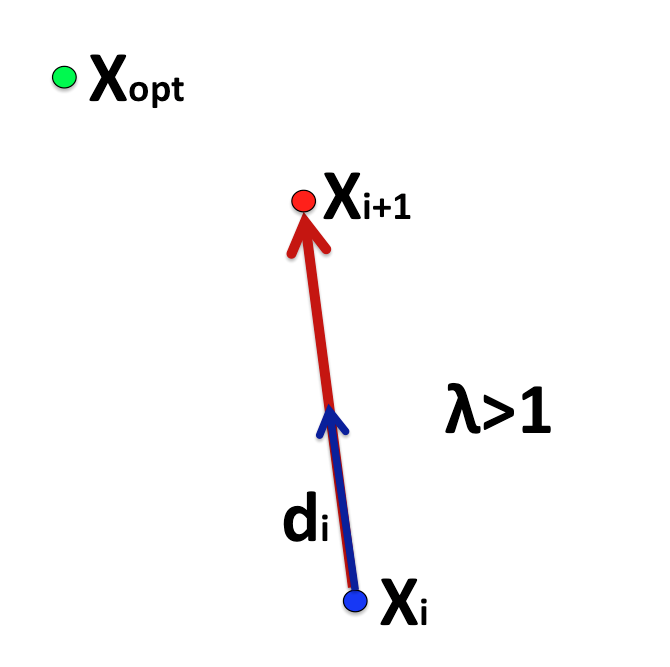
Say you are at Xi and there is a near (unkown) optimal location Xopt, even if it is unknown you have the "hunch" that if you travel in the direction d you will get closer to Xopt. Therefore you decide that your next location Xi+1 will be advancing λ > 1 times that direction, such a picture looks like this
Line Search
Finding the Proper Step
The main reason that this method is called "Line Search" is because give the current location Xi, you will search for your next location Xi+1 on the the line given by your direction. Intuitively this can be thought of as choosing a direction and walking on that direction strictly until it is decided that a new direction is needed.
What was now described actually reduces to finding a proper step λ because as it was previously stated, λ dictates how much you are actually going to travel. Given that the direction d is fixed (even thought nothing has been said about how to choose it), the only variable yet to determine is λ. Say you define the function g as

given that λ has to be greater than 0, then the function g gives you the values of f (heights) if you advance λ times in the direction d. Since g only depends on λ it an unidimensional function, even thought f is ingeneral multidimensional.
What was now described actually reduces to finding a proper step λ because as it was previously stated, λ dictates how much you are actually going to travel. Given that the direction d is fixed (even thought nothing has been said about how to choose it), the only variable yet to determine is λ. Say you define the function g as

Finding the Proper Step
Since function g(λ) is unidimensional, finding a proper λ is "easier" because of the reduced dimensionality of the problem. In our example, given the current positon Xi and the chosen direction d, what you want to find a step length λ that maximizes g (thus maximising f in a linear search), since we want to get to the highest place on the landscape.
For this you need a unidimensional optimisation algorithm such as Golden Section Search, Newton's Method, Cubic or Quadratic Optimisation. These methods may be covered in future posts, but for now the readers is encouraged to quickly look them up.
Choosing the Direction
Line Search is actually a family of algorithms which share the basic form but mostly differ on how you choose the search direction. Some popular methods are Gradient Descent, Newton-based Methods, Conjugate Gradient-based Methods.
Gradient Descent is a good start because its the easiest one to implement and most algorithms use modifications of this method to get improvements. Basically the gradient ∇f(Xi) of the function f at the point Xi is the direction in which the function increases the most. Calculating the gradient involves partial derivatives and it can be determined analytically or estimated numerically.
Walking Through the Landscape
Now that all the concepts needed have been discussed, the algorithm for solving our problem is really easy and involves in essence the computation of the following steps:
lineSearch( f, Xo )
- X <-- Xo //Set X to the initial position
- while( CONVERGING_CONDITIONS )
- d <-- NewDirection //Choose new direction
- g(λ) <-- f( X + λ * d ) //Construct linear optimization function
- λopt <-- UnidimensionallyOptimize( g(λ) ) //Choose a good advance step
- X <-- X + λopt * d //From X advance λopt in direction d
- end while
- return( X )
end lineSearch
Essentially line search is about choosing directions, advance steps, and finally advancing, in other words line search is just like walking, walking in the dark.
Solution to the Example
Typically most continuos optimization problems (that depend on continuos variables, like in the example) are stated as minimization problems, that is, they wish to minimize the objective function. Our example problem however is a maximization one, luckily all maximization problems can be stated as minimization problem by slightly changing the function. That is, they minimize the function
It is not hard to see that minimizing g implies maximizing f.
To solve this problem we are going to use gradient descent and thus we are going to need to know the gradient. Taking the partial derivatives to X1 and X2 we get

Now we apply the algorithm to 'walk through the landscape'. At each iteration we start with a location X = [ X1, X2 ], using the gradient to calculate the direction we get d = [ d1, d2 ], construct the function g(λ) and unidimensionally find a optimum step λ. Having that we just apply the formula for X and procede to the next iteration. Starting at X = [ 0, 0 ], here is a table with all the values for the variable involved in the optimisation process.

By plotting X at each iteration we can se the behaviour of the algorithm. Notice that while it is skips around a little, after just 5 iterations its really close to the optimum value.

As expected, the algorithm finds a local maximum, which in this case is also the global maximum. Because of the skipping, each iteration doesn't always do better than the previous one (which may be a good thing) but the general tendency is for it to improve until it converges.

Cristian Garcia
No hay comentarios:
Publicar un comentario